

Handling big data with Purge-it
Discover how Purge-it handles large volumes of JD Edwards data in this blog article
Read more >
The year in review
Looking back on 2025 milestones and ahead to more JD Edwards in 2026!
Read more >
How do you manage JD Edwards data without JD Edwards?
As your JD Edwards system is retired you may start to lose JD Edwards skills and knowledge. Find out how to address this challenge.
Read more >
Data Management for your JD Edwards Data
Is your organization thinking about the subject of data retention for your JD Edwards system? In this article we explore key discussion points around developing a meaningful Data Retention Policy.
Read more >
What is Data Archiving?
Find out how Data Archiving and Data Purging fit into Data Lifecycle Management
Read more >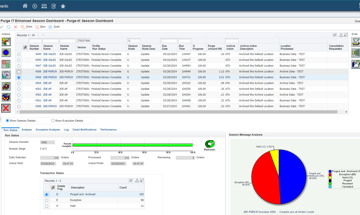
How to delete JD Edwards data that has passed its retention date and not just archive it
If your data archive is growing and you need to take action, check out how functionality in Purge-it Version 5.2 allows the possibility to completely remove old data from the archive
Read more >
How to measure the success of Data Archiving (Part 3)
In the final part of this 3 part series of blog articles 'measuring the success of data archiving', we look at two more customer examples
Read more >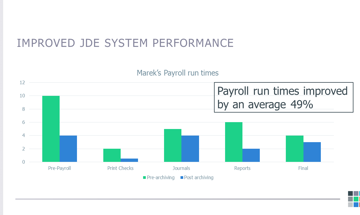
How to measure the success of Data Archiving (Part 2)
In part 2 of 'measuring the success of data archiving', we look at real customer examples
Read more >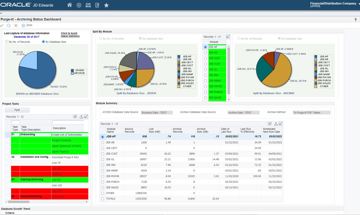
How to measure the success of Data Archiving (Part 1)
Can you measure the impact of data archiving? How do you demonstrate ROI? We address these questions and others in this JD Edwards article
Read more >What is Oracle Validated Integration (OVI)?
Find out how Klik IT achieving Oracle Validated Integration with JD Edwards EnterpriseOne Expertise for its integration of Purge-it can help you and your organization
Read more >
Purge-it Version 5.2 FAQs
Explore some of the most frequently asked questions relating to the latest release of the JD Edwards data archiving solution, Purge-it
Read more >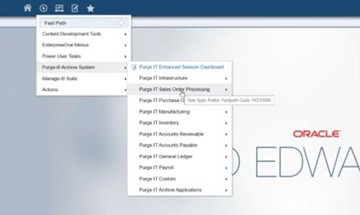
Is Purge-it easy to use for E1 data archiving?
Purge-it customers tell us one of the key drivers for choosing the data archiving solution is its usability. In this blog post we look at the main factors that make Purge-it easy to use.
Read more >
What is Purge-it?
Find out all about Purge-it. How it works, who it's for and what it offers JD Edwards users
Read more >Get a JD Edwards data healthcheck
In this blog post we look at how the JD Edwards data archiving solution Purge-it! gives your JD Edwards system a health check.
Read more >
30 features of Data Archiving with Purge-it
Discover the top 30 features of data archiving with Purge-it that make it a truly easy product to implement.
Read more >What is JD Edwards Archiving as a Service?
You're no doubt familiar with the as a Service model. Discover the business benefits of opting for Archiving as a Service for your JD Edwards E1 data archiving needs in this blog post.
Read more >
8 reasons to automate your JD Edwards archiving
Checkout this second blog post on archive automation. We zoom in on the 8 top reasons to automate your JD Edwards archiving.
Read more >
What is archive automation for JD Edwards?
Find out how human intervention in the routine task of archiving JD Edwards data can be greatly reduced. We’re talking about archive automation. It can help achieve remarkable ongoing efficiencies.
Read more >What is meant by an integrated JD Edwards archiving solution?
What's the difference between an external and an internal archiving product when it comes to JD Edwards archiving? Read our short blog post as we summarize the differences.
Read more >
Why is JD Edwards running slow?
Deteriorating system performance negatively impacts many job functions across an organization. Find out why you system is slow. Discover how to speed up your JD Edwards system and enhance the user experience.
Read more >
Find out which version of Purge-it! your organization is running
Make sure your organization is maximizing its use of the archiving solution Purge-it! Find out which software version you have. Discover the latest product enhancements and new Purge-it! features and functionality.
Read more >
How Klik IT started 25 years ago...and what's next?
As Klik IT celebrates 25 years in business in 2023, we took some time out to chat to CEO, Terry Clarke.
Read more >
Find a JD Edwards archiving solution that works for your business. Ask these 5 questions.
Is your organization looking for a 3rd party archiving solution?
Checkout 5 key questions to ask when evaluating JD Edwards archiving tools and solutions.
Read more >
Data Retention & Security
Data Retention and Security is a hot topic and a vast subject.
In this Blog post we look at Data Retention and Security from the perspective of organizations running JD Edwards. We cover the key considerations as we see them and provide links to industry articles and information for a broader view of the subject.
Read more >Why is JD Edwards running slow?

The good news is that JD Edwards EnterpriseOne and JD Edwards World provide a unique suite of applications that help your business to grow. However, JDE E1 and World, by their nature as ERP systems, collect data. Every transaction adds data to a JD Edwards table. The JD Edwards software allocates separate tables for each application area.
The not so good news is that as your volume of data grows, you notice your whole system slowing down. In this blog post we’ll look at why the system is taking longer to respond and what actions you can take to speed up your JDE system.
Your Data story
The data in your JD Edwards system consists of items that relate to everyday business processes. These are an essential part of everyday business. These items start as self-contained pieces of information that relate to a specific business process.
Examples of JD Edwards data items
- Sales Orders (SO)
- Purchase Orders (PO)
- Inventory items (INV)
- Manufacturing Works Orders (WO)
Gradually as data items are processed other items are created. Data sets are then generated to support the processing of the individual data items.
Examples of JDE data sets
- A Sales Order needs the purchase of a part. The Purchase Order for the part is created and linked to the Sales Order. PO to SO.
- A Sales Order requires goods to be manufactured. A Works Order is generated for the goods and linked to the Sales Order. PO to SO
- An Invoice, which is linked to the Sales Order, is raised to be sent to the customer.
- Financial postings are made to the General Ledger for the Invoice.
When you consider this simple example, it’s easy to visualise how the data items are interconnected across the JD Edwards tables. Imagine this on a much larger scale for a busy organization.

JDE Data gradually becomes more complex and interconnected
It’s easy to see how the quantity and complexity of these interconnected data items and data sets will build as the volume of data in the JD Edwards ERP grows.
As the JD Edwards table sizes increase and the quantity of interconnected data sets expand, then the User Experience tends to deteriorate. In this scenario, it takes more time for system users to find the information they need. Routine system back-ups take longer. Reports don’t complete in the allocated window. System users struggle and experience reduced productivity levels. Leading to an overall bad UX.

Archive old data to reveal a leaner, cleaner JDE data set
Get a faster JD Edwards system
The obvious way to speed up your JDE system is to free up system capacity by archiving old complete records.
How to reduce database size
Step 1
Identify the old and complete data in your JD Edwards system.
Only some of your data will hold important value to your business. A large quantity of the data is likely to have little or no business value. When evaluating what data can be archived, consider the type of data and the age of the data in your ERP.
Step 2
Understand and check the relationships the data has with other data in the JD Edwards system.
Step 3
Cross validate the related data.
Step 4
Move the data from your JD Edwards systems into an archive.
Step 5
Identify incomplete data and data with bad integrity. Flag the data for checking and fixing if appropriate.
News Snapshot...
Why Archive JD Edwards data?
5 Reasons
- Speed up your JD Edwards system
- Improve staff efficiency
- Optimize storage space
- Substantial cost savings
- Highlight business process and data integrity issues
Overcome Common Concerns.
Find the right archiving product for your unique JDE data set.
3 common concerns:
- How will staff access archived records?
- How can you find out if current balances are correct if the older figures have been removed?
- What about auditing?
Reducing your database size by archiving may seem like a daunting task but it needn’t be with the right solution for your organization and your JD Edwards data.
Checkout our blog post:
Evaluate 3rd party archiving products. Ask 5 key questions

Get answers to your JD Edwards data management questions.
JDE E1 and World.
Chat to a JDE archiving specialist.
